Processing and understanding the human language has been an ultimate goal of Machine Intelligence. The Turing test, originally called the imitation game by Alan Turing in 1950, is a test of a machine’s ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. Turing proposed that a human evaluator would judge natural language conversations between a human and a machine designed to generate human-like responses. The evaluator would be aware that one of the two partners in conversation is a machine, and all participants would be separated from one another. If the evaluator cannot reliably tell the machine from the human, the machine is said to have passed the test.
Since the first introduction of the Turing Test, there have been continuous efforts to develop tools and technology to process human language. These efforts lead to the emergence of the field of Natural Language Processing (NLP) or Computational Linguistics (CL), an area of Artificial Intelligence (AI) that deals with providing computers the ability to process and understand natural language. It is a confluence of Computer Science and Linguistics.
Stages of NLP
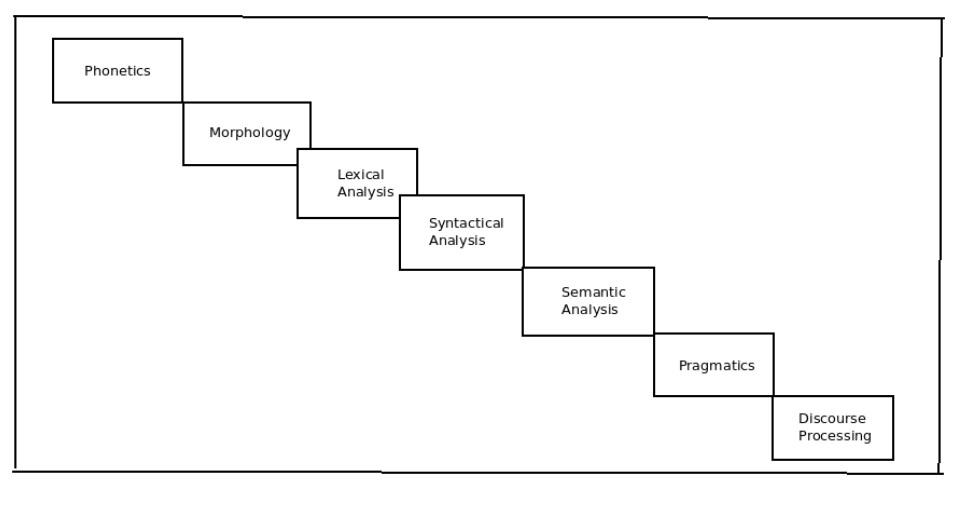
Various stages of Natural Language Processing (NLP) are as follows,
1. Phonetics and Phonology
Phonetics is the study of human sounds, and phonology is the classification of the sounds within a particular language or language system. The study of phonetics and phonology is necessary to convert spoken language into written (speech to text). Phonetics is a tough problem, as a sound can be mapped to more than one alphabets of the language.
George Bernard Shaw once famously pointed out that the word fish could as easily be spelled ghoti, since gh has the same sound in ‘enough’, o has the same sound in ‘women’, and it has the same sound in ‘nation’.
2. Morphology
Morphology is the study of word structures, especially regarding morphemes, the most minor units of language. It identifies words and various inflections that words can take. For example, in English, a noun can be singular or plural, e.g., boy and boys and verbs can indicate tense, past, present, future, e.g., reach, reached. Morphological processing deals with identifying such inflections of a word and finding out the root form.
3. Lexical Analysis
Lexical Analysis essentially refers to dictionary access and obtaining property of a word. The word is a meaning conveying a unit of the language. During lexical Analysis, the lexeme for a word and its part of speech is identified. Specific level of semantic processing is also carried out to identify the word’s meaning.
4. Syntactical Analysis
Syntactic analysis, also referred to as syntax analysis or parsing, analyzes natural language sentences with formal grammar rules. Grammatical rules are applied to categories and groups of words. The syntactic analysis assigns a structure to text. Constituency and Dependency parser are two popular approaches to studying the text’s syntactic structure.
5. Semantic Analysis
Semantic analysis is understanding the meaning and interpretation of words, signs and sentence structure. This lets computers partly understand natural language the way humans do. Word Sense Disambiguation is the key challenge of Natural Language Processing.
6. Pragmatics
Pragmatics refers to how words are used in a practical sense. People often construct sentences where the word’s meaning is different from its defined dictionary meaning. In contrast to semantic analysis in which well-defined meanings of the words are found, during pragmatics analysis, attempts are made to find the intended meaning of the speaker or writer. Pragmatic Analysis often involves the processing of manner, place and time of an utterance to create meaning.
7. Discourse Analysis
It deals with processing the sequence of sentences to understand the overall context of the sentence. The overall conversation is processed during discourse analysis to understand the natural language.
Applications of NLP
While using the internet or mobile for text communication, we knowingly or unknowingly use NLP or other applications. For example, we all have used the features as shown in the figure below,
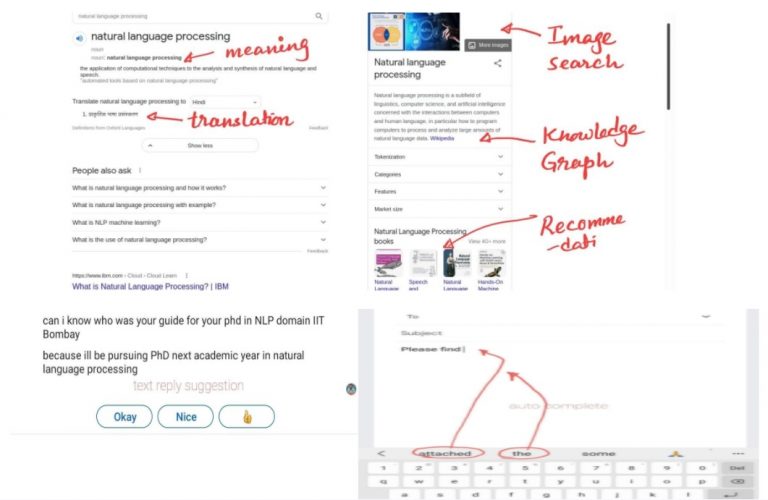
As shown in the above figure, a simple google search nowadays involves complex NLP processing like semantic processing, translation, recommendation, and knowledge graph. In WhatsApp and LinkedIn chat, we get “Text Suggestion” as possible replies; similarly while drafting an email, we get “auto complete” suggestions for the next possible word. Some of the popular NLP tasks which now have become part of our daily life are as follows,
Machine Translation
Machine translation is a major application of Natural Language Processing that requires almost all levels of Natural Language Processing. A machine translation system reads text input from one language and produces output text in another language. The famous machine translation processing tools were proposed in IBM Models; more recently, Deep Learning-based Neural Machine Translation (NMT) systems are becoming popular.
Information Extraction
Question Answering
Sentiment Analysis
Text Summarization
Recommendation System
NLP Frameworks
- NLTK : The Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language. It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania. NLTK includes graphical demonstrations and sample data. It is accompanied by a book that explains the underlying concepts behind the language processing tasks supported by the toolkit, plus a cookbook. NLTK is intended to support research and teaching in NLP or closely related areas, including empirical linguistics, cognitive science, artificial intelligence, information retrieval, and machine learning. https://www.nltk.org/
- Stanford NLP library: The Stanford NLP Group makes some Natural Language Processing software available to everyone! Apart from the essential NLP processing toolkit, the library also provides statistical NLP, deep learning NLP, and rule-based NLP tools for major computational linguistics problems, which can be incorporated into applications with human language technology needs. These packages are widely used in industry, academia, and government. https://nlp.stanford.edu/software/
- AllenNLP: AllenNLP is the deep learning library for NLP. Allen Institute for Artificial Intelligence, which is one of the leading research organizations of Artificial Intelligence, develops this PyTorch-based library. Using AllenNLP to develop a model is much easier than building a model by PyTorch from scratch. It provides easier development and supports the management of the experiments and their evaluation after development. AllenNLP has the feature to focus on research development. More specifically, it’s possible to prototype the model quickly and make it easier to manage the experiments with many different parameters. Also, it has consideration using readable variable names. https://allennlp.org/
- spaCy: spaCy is an open-source software library for advanced natural language processing, written in Python and Cython. Unlike NLTK, which is widely used for teaching and research, spaCy focuses on providing software for production usage. spaCy also supports deep learning workflows that allow connecting statistical models trained by popular machine learning libraries. spaCy features convolutional neural network models for part-of-speech tagging, dependency parsing, text categorization and named entity recognition (NER). Prebuilt statistical neural network models to perform these tasks are available for 17 languages, including English, Portuguese, Spanish, Russian and Chinese, and there is also a multi-language NER model.
- RaSa: Rasa NLU (Natural Language Understanding) is a set of high-level APIs for building language parsers using existing NLP and ML libraries. It aims to build Natural Language Understanding applications and is particularly useful in understanding Short pieces of text. RaSa NLU is primarily used to build chatbots and voice apps. To use Rasa, you have to provide some training data, a set of messages which you’ve already labeled. Rasa then uses machine learning to pick up patterns and generalize to unseen sentences.
Deep Learning Frameworks
- PyTorch: PyTorch is an open-source machine learning library developed by Facebook’s AI Research lab (FAIR). It is free and open-source software released under the Modified BSD license. PyTorch has Python and C++ interface to develop applications. Several pieces of deep learning software are built on top of PyTorch, including Tesla Autopilot, Uber’s Pyro, Hugging Face’s Transformers, PyTorch Lightning, and Catalyst.
- TensorFlow: TensorFlow, developed by the Google Brain team, is an end-to-end open-source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries and community resources that lets researchers push the state-of-the-art in ML and developers quickly build and deploy ML-powered applications. TensorFlow can run on multiple CPUs and GPUs with optional CUDA and SYCL extensions.
- Keras: Keras is an open-source software library that provides a Python interface for artificial neural networks. Keras acts as an interface for the TensorFlow library. Keras contains numerous implementations of commonly used neural network building blocks such as layers, objectives, activation functions, optimizers, and a host of tools to make working with image and text data easier. In addition to standard neural networks, Keras supports convolutional and recurrent neural networks.
- fastAI: fastAI is a free open source library for deep learning, sitting atop PyTorch. Google Cloud supports it. fast.ai is a non-profit research group founded to democratize deep learning. They do this by providing a massive open online course (MOOC) named “Practical Deep Learning for Coders”
Pretrained Model
The rapid development of Transformers have brought a new wave of powerful tools for natural language processing. These models are large and expensive to train, so researchers and practitioners share and leverage pre-trained versions. Pre-trained deep learning models are increasingly popular to solve natural language processing problems. Some of the popular pre-trained models are OpenAI GPT, BERT and ELMO. While BERT and OpenAI GPT are based on transformers networks, ELMo takes advantage of a bidirectional LSTM network.
Model Hubs
- HuggingFace: Hugging Face offers a wide variety of pre-trained transformers as open-source libraries, which can be incorporated with only one line of code. HuggingFace is focused on solving NLP problems like text classification, information extraction, question answering, and text generation using the pre-trained model.
- TFHub: TensorFlow Hub is an open repository and library for reusable machine learning. The tfhub.dev repository provides many pre-trained models for text embeddings and image classification.
Examples of NLP in Real Life
- Conversation Agents [Consumer Experience, Sales]: Conversational agents are a dialogue system that processes natural language and then responds to human language queries. Conversational agents exemplify the pragmatic usage of computational linguistics, which are usually employed as virtual agents over the internet as service assistants. Nowadays, many businesses like Insurance, Banking, etc., provide online chatbot/virtual assistants to identify suitable products for the user or manage service requests.
Apart from many online chatbots and virtual assistant applications, conversation agents have now become part of our lives through home devices. Some of them are
Alexa : https://developer.amazon.com/en-US/alexa
Siri : https://www.apple.com/in/siri/
Cortana : https://www.microsoft.com/en-us/cortana
- Google Translate [Consumer]: Google Translate is a multilingual neural machine translation service developed by Google to translate text, documents and websites from one language into another. It offers a website interface, a mobile app for Android and iOS, and an application programming interface that helps developers build browser extensions and software applications. As of October 2021, Google Translate supports 109 languages at various levels and, as of April 2016, claimed over 500 million total users, with more than 100 billion words translated daily. Launched in April 2006 as a statistical machine translation service, it used United Nations and European Parliament documents and transcripts to gather linguistic data. Rather than translating languages directly, it first translates text to English and then pivots to the target language in most of the language combinations it posits in its grid. In November 2016, Google announced that Google Translate would switch to a neural machine translation engine – Google Neural Machine Translation (GNMT) – which translates “whole sentences at a time, rather than just piece by piece. It uses this broader context to help it figure out the most relevant translation, which it then rearranges and adjusts to be more like a human speaking with proper grammar”. Initially only enabled for a few languages in 2016, GNMT is now used in all 109 languages. Google Translate: https://translate.google.co.in/
- JP Morgan’s COIN [Banking, Law]: JP Morgan started implementing a program called COIN, which is short for Contract Intelligence. COIN runs on a machine learning system that’s powered by a new private cloud network that the bank uses. Apart from shortening the time it takes to review documents, COIN has also managed to help JP Morgan decrease its number of loan-servicing mistakes. According to the program’s designers, these mistakes stemmed from human error in interpreting 12,000 new wholesale contracts every year. COIN is part of the bank’s push to automate filing tasks and create new tools for both its bankers and clients. Automation is now a growing part of JP Morgan’s $9.6 billion technology budget. In fact, over the past two years, technology spending in JP Morgan’s consumer banking sector has totaled about $1 billion. “We have invested heavily in technology and marketing —and we are seeing strong returns,” the bank said in a presentation prior to its annual investor day.tps://futurism.com/an-ai-completed-360000-hours-of-finance-work-in-just-seconds
- Erica [Banking, Customer Service]- Bank of America’s virtual assistant, AI-powered assistant shows strong signs of consumer acceptance by reaching 7 million users. The bank has more than 37 million active users of its digital banking services, including more than 27 million mobile users, giving the company a large audience for introducing new services and tech like digital wallets, voice features and loyalty programs. The number of users are likely to rise as tech-savvy Generation Z continues to reach adulthood and begins using more financial services. Erica’s significant usage demonstrates how consumers are growing more comfortable interacting with virtual assistants for some tasks while signaling that AI and natural language processing can give mobile apps a wider range of functionality for on-the-go customers.